Cross validation is een manier voor data scientists om te valideren of een getraind machine learning model goed presteert op nieuwe data. In deze blogpost duiken we dieper in de volgende thema's:
- Waarom is het valideren van een model belangrijk?
- Wat is k-fold cross validation?
- k-fold cross validation in Python met sklearn (voorbeeld)
Waarom is het valideren van een model belangrijk?
In een ideale wereld train je een machine learning model met zo veel mogelijk kwalitatieve data. Echter, als we alle beschikbare data gebruiken voor het trainen van een model, hoe test je dat of het model dat je hebt ontwikkeld goed presteert? Als we de prestaties van een getraind model valideren met een deel van de data waarmee dat model getraind is dan ben je natuurlijk jezelf voor de gek aan het houden. Want natuurlijk presteert een model waarschijnlijk goed met de data waarmee het is getraind. Je riskeert dan een situatie waarin je "overfit".
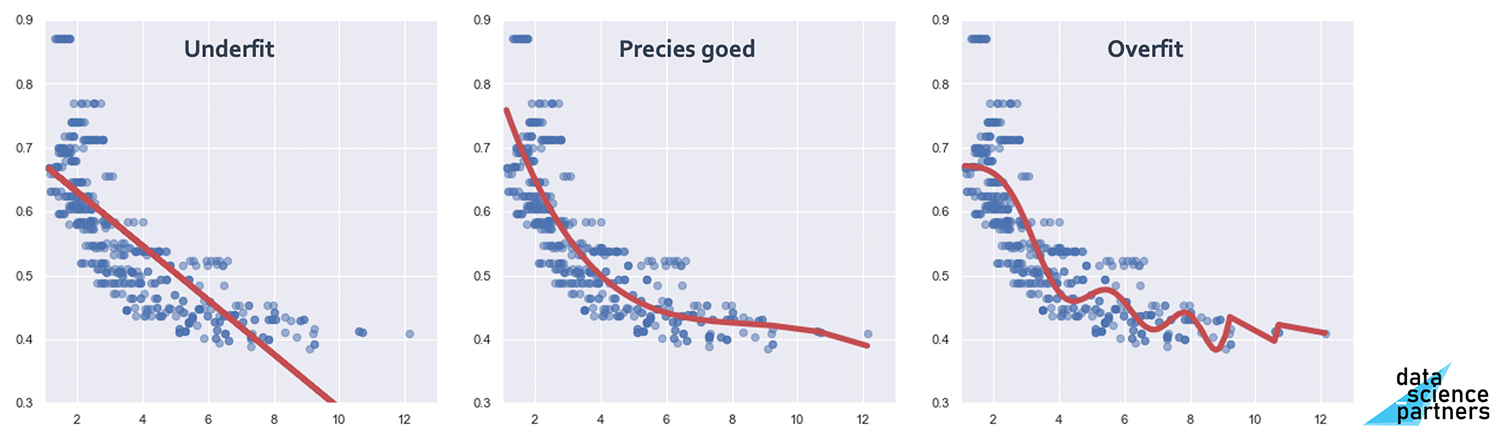
Dit houdt in dat je je model te veel afstemt op de data die je beschikbaar hebt, waardoor het alléén op die data erg goed presteert, maar op nieuwe data een stuk minder.
Binnen een machine learning model zoek je altijd naar de juiste balans tussen de bias in het model en de variantie. In bovenstaande afbeelding heb je aan de linker kant een 'underfit' met een hoge bias en lage variantie. Aan de rechter kant hebben we te maken met 'overfitting' (een hoge variantie en een lage bias). Zowel het model uit de linker als het model uit de rechter afbeelding zullen minder goed presteren op nieuwe data dan het middelste model.
Het is de uitdaging voor data scientists om met de beschikbare data zo slim mogelijk verschillende samples uit de zelfde data te halen waardoor een under- of overfit herkend kan worden. Dit wordt o.a. gedaan d.m.v. cross validation.
Wat is cross validation?
Cross validation is een manier om verschillende "train" en "test" samples te selecteren uit een beschikbare dataset.
Zo kun je bijvoorbeeld Leave One Out Cross Validation (LOOCV) gebruiken. Wat je hierin doet is het model trainen met n-1 datapunten en het model valideren met het overgebleven datapunt. Dit herhaal je n keer zodat je met ieder datapunt een keer een getraind model valideert. Uiteindelijk neem je het gemiddelde van alle prestaties om tot een evaluatie van het model te komen.
Deze aanpak kan goed werken bij kleine datasets. Je maximaliseert namelijk de hoeveelheid data in de training dataset. Echter, deze aanpak kent ook nadelen:
- Doordat je bijna alle data gebruikt bestaat het risico op overfitting
- Doordat je n keer een model traint kost deze aanpak veel rekenkracht
Om deze nadelen te overkomen wordt er veel gebruik gemaakt van k-fold cross validation. In k-fold cross validation splits je je training data op in k folds (folds zijn subsets van de totale datasets). Je gebruikt de k-1 folds om het model te trainen en valideert met de overgebleven fold. Dit doe je k keer. Uiteindelijk test je de prestaties van jouw machine learning model op de uiteindelijke testdata.
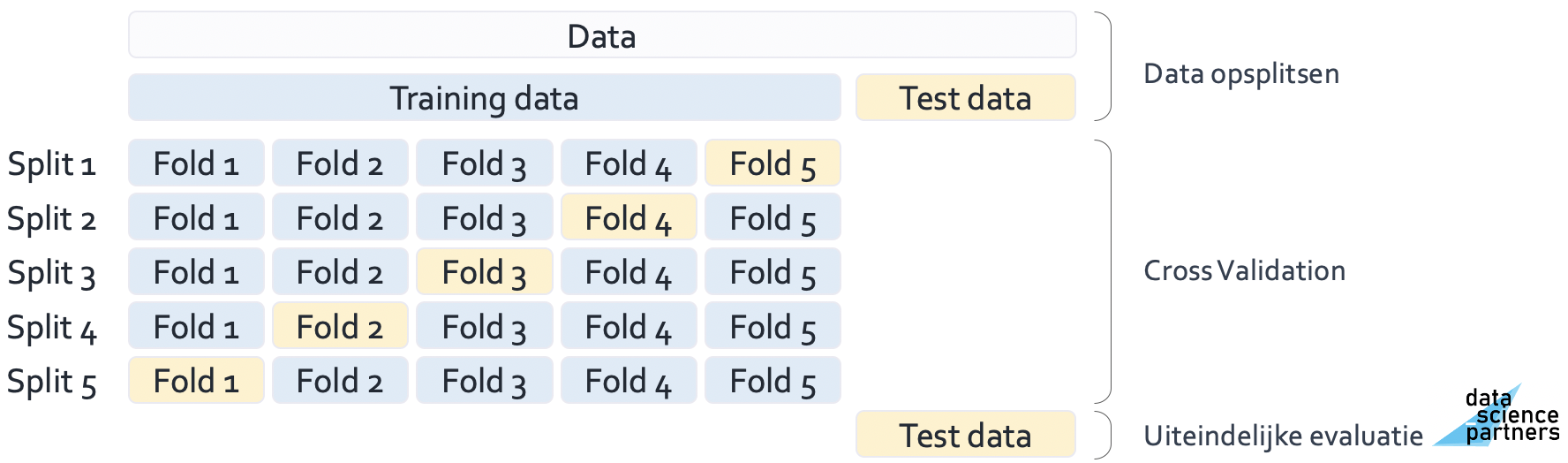
Op deze manier beperk je de benodigde rekenkracht en introduceer je wat meer bias door de grotere set testdata. Met het aantal folds kun je - afhankelijk van de situatie - spelen om tot een optimale prestatie te komen. Vijf tot tien folds wordt veel gebruikt in de praktijk.
Enkele andere manieren van cross validation zijn weergegeven in onderstaande afbeelding.

- ShuffleSplit(): hierbij wordt testdata random gekozen. Het geeft meer vrijheid m.b.t. het aantal iteraties en de verhouding tussen train-/ testdata.
- StratifiedKFold(): bij deze manier van cross validation wordt er in de selectie van de testdata rekening gehouden met bepaalde verhoudingen in de volledige dataset.
- GroupKFold(): hierbij wordt de data opgesplitst naar verschillende groepen waarbij je steeds één groep als testdata gebruikt.
- TimeSeriesSplit(): hiermee kun je valideren hoe een model presteert over tijd door een dataset op te splitsen in verschillende intervallen die je vervolgens bij elkaar optelt.
k-fold cross validation in sklearn (voorbeeld)
Het package sklearn in Python biedt handige functionaliteit om te werken met cross validation.
Om dit te illustreren laden we een voorbeeld dataset in waarin de huizenprijzen en andere kenmerken van huizen uit de stad Boston opgeslagen zijn. Dit doen we als volgt.
from sklearn.datasets import load_boston
X, y = load_boston(return_X_y=True)
print(X.shape)
Vervolgens kunnen we met KFold() een opsplitsing van de data maken. We splitsen de data in 5 folds waarbinnen de data geshuffeld wordt. Met random_state zorgen we dat de resultaten reproduceerbaar zijn.
Met cross_val_score() berekenen we de R2 (de hoeveelheid variatie in de data die wordt verklaard door het model) voor de verschillende folds. Uiteindelijk nemen we het gemiddelde van de R2's om tot een eindwaarde te komen.
We hebben hierbij niet ons best gedaan om tot een goed machine learning model te komen. Dit voorbeeld dient puur om te laten zien hoe cross validation in Python met sklearn vorm kan krijgen.
import numpy as np
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import cross_val_score, KFold
kf = KFold(n_splits = 5, shuffle = True, random_state = 1)
knn = KNeighborsRegressor()
r_2s = cross_val_score(knn, X, y, scoring = 'r2', cv=kf)
avg_r2 = np.mean(r_2s)
print(r_2s)
print(avg_r2)
Met cross_val_score() is het mogelijk om voorspellingen te doen voor een veelheid aan verschillende machine learning modellen. Als output kun je kiezen uit veel verschillende scoring metrics. Ook kun je de verschillende soorten cross validation (zoals eerder in deze blog beschreven) als input geven met "cv=". De standaard is (Stratified)KFold cross validation dus als je alleen een cijfer ingeeft dan zal dat automatisch gebruikt worden.
Cross validation met Python is onderdeel van onze machine learning training en data science opleiding. Dus wil jij je ontwikkelen of omscholen tot data scientist en in staat zijn om de prestaties van eigen machine learning modellen te beoordelen? Schrijf je dan in of neem contact met ons op voor meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Rik is data scientist en marketeer bij Data Science Partners. Vanuit zijn achtergrond op de Technische Universiteit Eindhoven heeft hij veel affiniteit met data. Na zijn studie heeft hij als consultant altijd met data gewerkt en tevens ervaring opgedaan in het geven van trainingen.