Ensemble Methods
Ensemble Methods is een onderdeel van Machine Learning waarbij je meerdere individuele modellen combineert om gezamenlijk betere voorspellingen te kunnen doen. Ensemble betekent letterlijk "samen, op dezelfde tijd". Stel je dit concept als volgt voor: je vraagt elk van je vrienden hun mening voordat je zelf een belangrijke beslissing neemt.
Ensemble Methods worden vooral daar toegepast waar met andere, simpelere modellen niet de gewenste voorspellingskwaliteit behaald kan worden. Je kunt Ensemble Methods voor zowel regressie- als classificatievraagstukken gebruiken. Bij regressie voorspellen we een getal, een waarde. Bij classificatie voorspellen we een categorie, een groep.
Er zijn 3 verschillende Ensemble Methods, dit zijn:
- Stacking
- Bagging (bootstrap aggregating)
- Boosting
We gaan stap voor stap door deze verschillende methoden heen om de ins en outs te verduidelijken.
Stacking
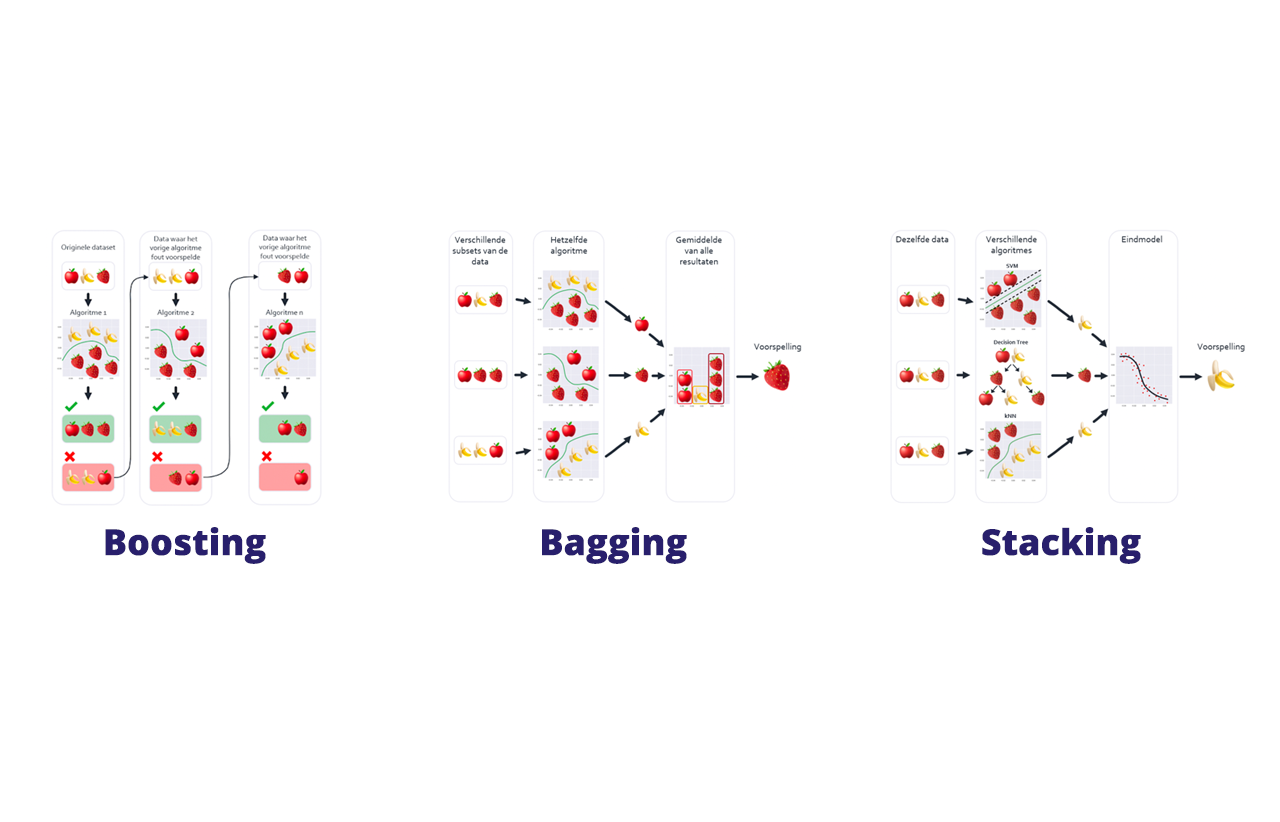
Met de Stacking methode train je meerdere verschillende algoritmes met dezelfde data. De uitkomsten van de verschillende algoritmes zijn de input van een eindmodel wat de uiteindelijke voorspelling geeft. Stel je dit voor als wanneer je verschillende vrienden advies vraagt over het huis wat je wilt kopen, en je op basis van de verschillende adviezen een besluit neemt.
De nadruk ligt hier vooral op het gebruik van verschillende algoritmes op dezelfde data. Hierbij gebruik je algoritmes zoals Logistic Regression, Decision Tree, SVM, etc.
In de praktijk wordt Stacking minder vaak gebruikt in verhouding tot Bagging en Boosting, omdat het vaak minder nauwkeurig is.
Bagging
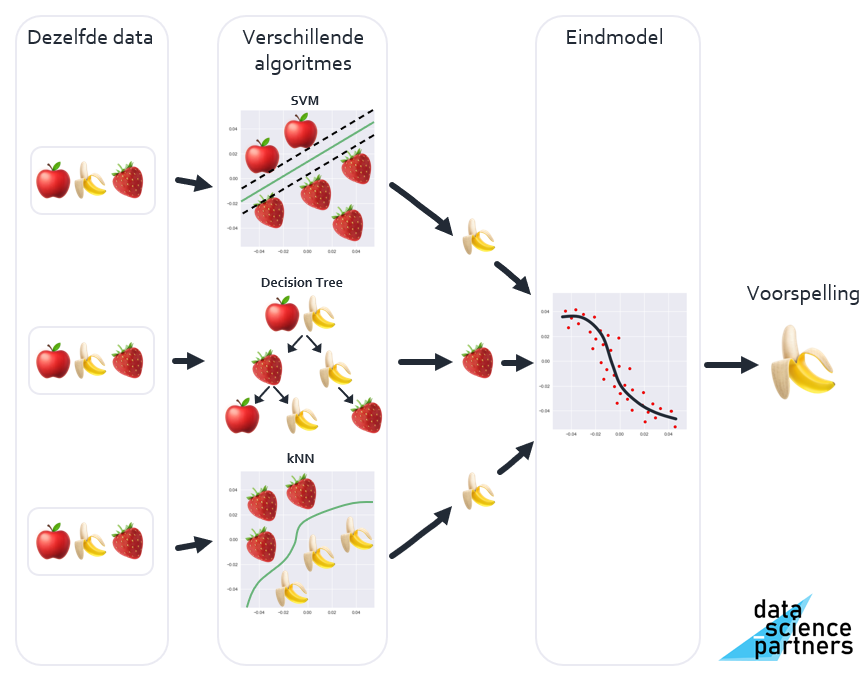
Met de Bagging methode deel je de dataset op in afzonderlijke subsets, segmenten. Vervolgens train je afzonderlijke versies van een specifiek algoritme op elk van de subsets. Om nu een voorspelling te doen geven elk van de inmiddels gemaakte modellen een voorspelling, waar je het gemiddelde van neemt.
Stel je dit voor alsof je de mening van één vriend verzamelt over alle losse kamers in het huis dat je wilt kopen, en je neemt je besluit op basis van het gemiddelde van de verschillende kamer-meningen.
Bagging staat voor bootstrap aggregating. Bootstrapping is een statistische methode om steekproeven te doen, aggregating staat voor verzamelen.
Als toepassing van de Bagging methode wordt als algoritme veel gebruik gemaakt van een Decision Tree. Wanneer je meerdere Decision Trees met Bagging toepast heet dit een Random Forest.
Een groot voordeel van de Bagging methode is dat de afzonderlijke modellen parallel uitgevoerd kunnen worden waardoor voorspellingen erg snel berekend kunnen worden. Veelal sneller dan wanneer hetzelfde met bijvoorbeeld Neural Networks zou worden gedaan. Dit concept heet parallellisatie. Hierdoor wordt Bagging vaak toegepast daar waar real-time voorspellingen nodig zijn, zoals bijvoorbeeld bij de gezichtsherkenning wanneer je op je telefoon de camera gebruikt.
Boosting
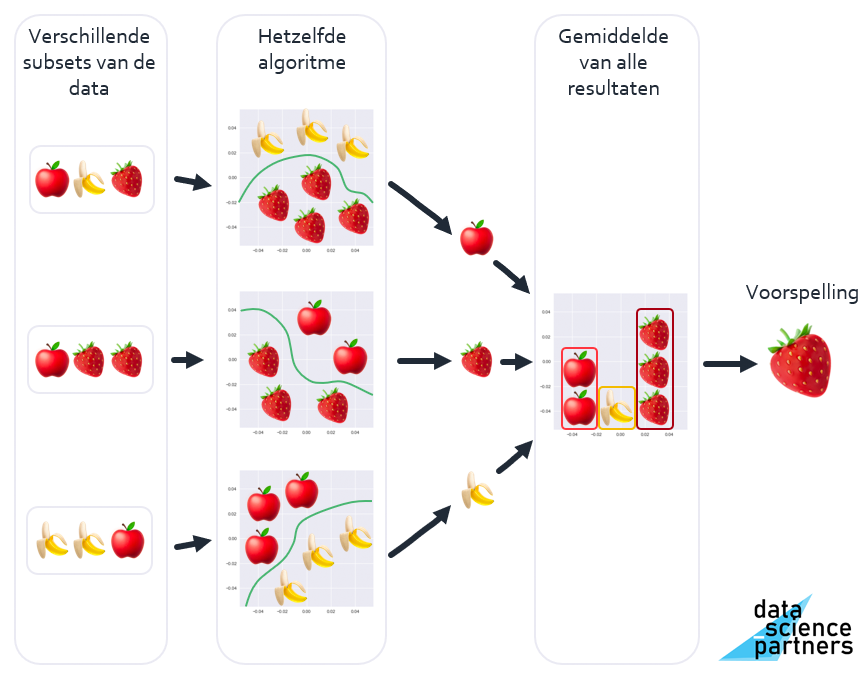
Met de Boosting methode train je opeenvolgende algoritmes met de data van onjuiste voorspellingen uit het vorige algoritme. Je hebt dus steeds een nieuw algoritme wat getraind wordt op de foute eerder gedane voorspellingen.
Stel je dit voor als een huisarts die systematisch oorzaken uitsluit om tot een juiste diagnose en behandeling te komen.
Boosting betekent letterlijk stimuleren, versterken.
Door met Boosting op een steeds kleiner wordend aantal onjuiste voorspellingen te focussen kunnen nauwkeurige voorspellingsresultaten behaald worden. Een keerzijde hiervan is dat dit ook overfitting in de hand kan werken, het concept dat het uiteindelijke model te goed aansluit op de trainingsdataset, en daardoor onvoldoende gegeneraliseerd is voor nog onbekende data.
Om met Boosting een voorspelling te doen moeten de individuele modellen na elkaar, in serie, uitgevoerd worden. Dit in tegenstelling tot Bagging, waar de individuele modellen naast elkaar uitgevoerd kunnen worden (parallellisatie). Hierdoor is een Boosting model over het algemeen minder snel dan een Bagging model.
Bekende Boosting modellen zijn bijvoorbeeld AdaBoost en XGBoost.
Wat je moet onthouden
We hebben geleerd dat Ensemble Methods gebruikt kunnen worden wanneer simpelere modellen zoals bijvoorbeeld Logistic Regression niet de gewenste nauwkeurigheid oplevert. Ensemble Methods combineren meerdere modellen om een voorspelling te kunnen doen en kunnen voor zowel regressie- als classificatievraagstukken gebruikt worden. De 3 Ensemble Methods zijn (1) Stacking, (2) Bagging en (3) Boosting.
Stacking wordt in de praktijk het minst gebruikt door de minst nauwkeurige voorspellingen. Bagging is snel doordat parallellisatie mogelijk is. Het bekendste Bagging model is een Random Forest, een verzameling Decision Trees. Boosting is nauwkeuriger dan Bagging, maar minder snel doordat parallellisatie niet mogelijk is. Een gevaar bij Boosting is overfitting.
Ensemble Methods toepassen in Python is onderdeel van onze data science opleiding en machine learning training. Dus wil jij je ontwikkelen of omscholen tot data scientist en in staat zijn om nog nauwkeurigere voorspellingen te kunnen doen? Schrijf je dan in of neem contact met ons op voor meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.









