Binnen het vakgebied van Machine Learning worden veel verschillende termen gebruikt, die in het begin behoorlijk overweldigend over kunnen komen. In dit blog scheppen we orde in de chaos door veelgebruikte data science en machine learning termen te benoemen en uit te leggen. Ook maken we de onderlinge verbanden duidelijk.
Nadat je dit gelezen hebt heb je een goed beeld gevormd van het landschap en de verschillende mogelijkheden van Machine Learning en kun je onderstaande afbeelding volledig plaatsen.
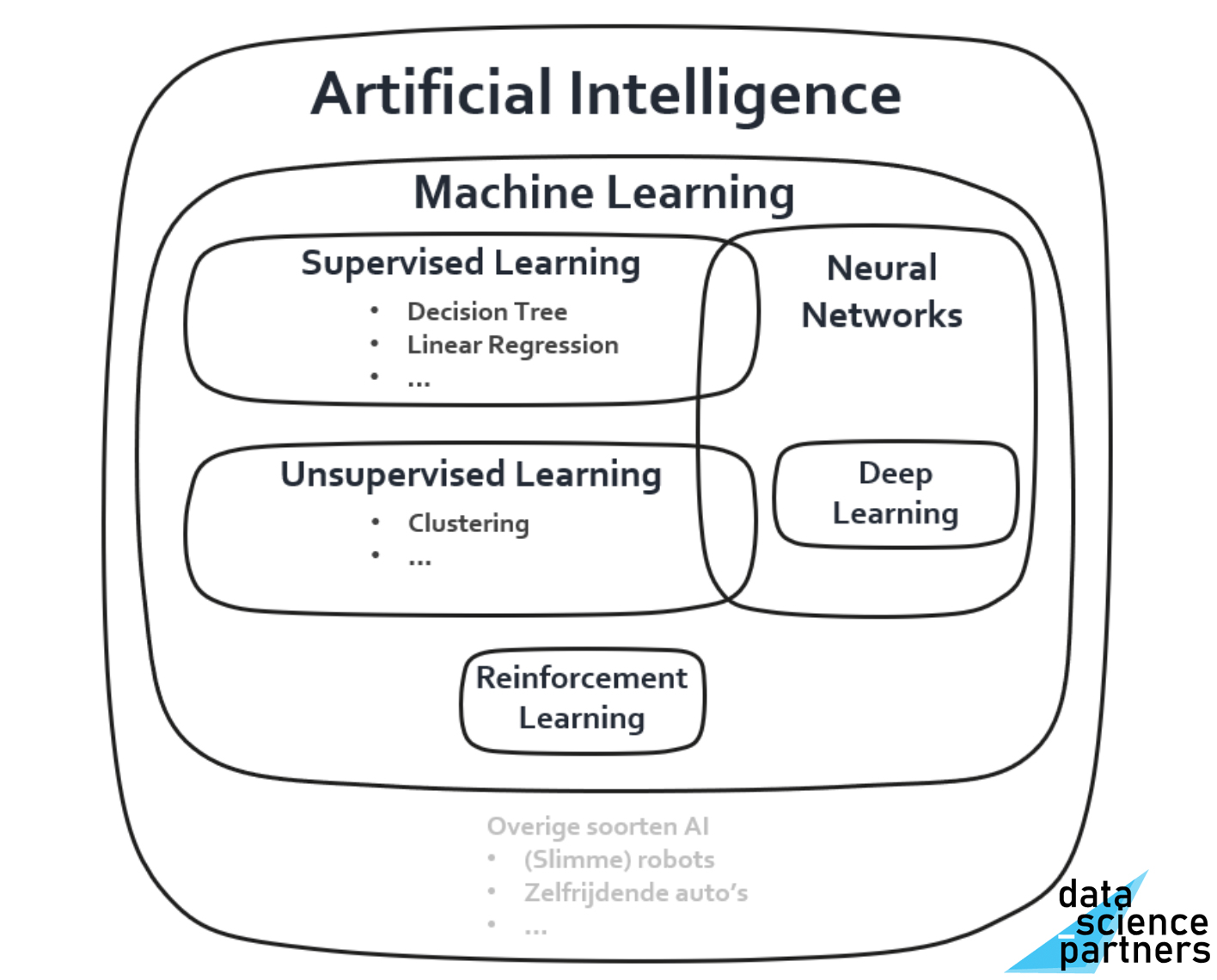
1. Artificial Intelligence
Artificial intelligence (AI) staat voor kunstmatige intelligentie. Dit is de overkoepelende benaming van geavanceerde computer intelligentie. Hieronder vallen verschillende deelgebieden, zoals Machine Learning. Naast Machine Learning vallen gebieden en onderwerpen zoals autonome voertuigen en slimme robots ook onder AI.
2. Data analytics
Data analytics is het vakgebied wat zich bezighoudt met analyses over waarom gebeurtenissen in het verleden plaatsvonden en wat in de toekomst plaats zal vinden. Hierbij wordt veelvuldig gebruik gemaakt van computer vaardigheden, wiskunde, statistiek en het toepassen van Machine Learning.
3. Machine Learning
Machine Learning is de naam van het omvattende gebied van meerdere methoden waarbij een computer uitgerust wordt met ervaring door patronen te herkennen in bestaande data, om met deze ervaring voorspellingen te kunnen doen op nieuwe data. Je hebt voor Machine Learning altijd een dataset nodig.
Check onze tweedaagse Machine Learning training als je hier alles over wilt leren
4. Dataset
Een dataset is een verzameling gegevens. Een eenvoudig voorbeeld hiervan is een Excel spreadsheet. Hierin zijn gegevens verzameld in rijen en kolommen. Over het algemeen werk je met input data die voorspellende waarde heeft van hetgeen je wilt voorspellen, en met output data, hetgeen je wilt voorspellen.
5. Feature
Een feature is een verzameling specifieke gegevens die je gebruikt om met een Machine Learning model voorspellingen te doen. Dit is één van de input variabelen, ook wel de X-waarden genoemd. Denk hierbij bijvoorbeeld aan een tabel met eigenschappen van kleding. Een kolom met de kleur zou hier een feature kunnen zijn. De output waarden zijn het resultaat van de voorspelling worden ook wel de y-waarden genoemd.
6. Algoritme
Een algoritme is een rekenmethode. Dit kun je je voorstellen als een lijst coderegels die achtereenvolgens uitgevoerd worden. Er zijn verschillende Machine Learning algoritmes, die elk een eigen manier hebben om patronen in data vast te leggen.
7. Trainen
Trainen is het toepassen van een algoritme op een dataset waarbij het algoritme patronen herkent en vastlegt. Veelal gebruik je een bepaald gedeelte van je dataset (bijvoorbeeld 80%) om het algoritme mee te trainen, dit wordt traindata genoemd. Het overige gedeelte (de overige 20%) gebruik je als 'nieuwe' data, om te zien hoe goed je voorspellingen kunt doen op data waarmee niet getraind is, dit wordt testdata genoemd.
8. Model
Wanneer een algoritme getraind is op een dataset en hiermee patronen heeft herkend en vastgelegd, is het resultaat een model. Waar een algoritme een universele reeks rekenregels omschrijft heeft een model zich aan een specifieke dataset aangepast en kan hiervoor voorspellingen doen.
9. Metrics
Metrics zijn de statistieken waarmee je de voorspellingsnauwkeurigheid van een model uit kunt drukken in een getal. Zo kun je bijvoorbeeld de nauwkeurigheid (accuracy) berekenen, hiermee verkrijg je het percentage juiste voorspellingen. Je vergelijkt dan bijvoorbeeld de accuracy van voorspellingen op de traindata met de accuracy van voorspellingen op de testdata. Zo krijg je een idee van hoe goed het model presteert op nieuwe data. Tevens gebruik je metrics om het effect van aanpassingen inzichtelijk te maken.
10. Supervised Learning
Supervised Learning betekent begeleid leren. Er is een supervisor aanwezig, iets wat richting geeft. Dit wil zeggen dat de data die gebruikt om een model te trainen de te voorspellen uitkomst al bevat. Denk hierbij aan het voorbeeld dat je huizenprijzen wilt voorspellen, en al een dataset hebt die eigenschappen van verkochte huizen bevat en ook de verkoopprijs.
Er zijn tal van verschillende Supervised Learning algoritmes waaronder Linear Regression, Decision Tree en Logistic Regression.
11. Classificatie
Classificatie is een deelgebied van Supervised Learning waarbij je een categorie, een groep, voorspelt. Denk hierbij aan het voorbeeld dat je wilt voorspellen of je een kat of een hond kunt herkennen in een afbeelding. Hierbij kun je met classificatie het label (kat / hond) voorspellen, of de kans (80% kans op kat).
12. Regressie
Regressie is een deelgebied van Supervised Learning waarbij je een numerieke waarde, een getal, voorspelt. Denk hierbij aan het voorbeeld dat je een huizenprijs wilt voorspellen. Het goed checken van assumpties die onder lineaire regressie liggen is belangrijk voor betrouwbare resultaten.
13. Unsupervised Learning
Unsupervised Learning betekent onbegeleid leren. In tegenstelling tot bij Supervised Learning is er bij Unsupervised Learning geen supervisor, niets wat richting geeft. Denk hierbij aan het voorbeeld dat je een dataset hebt met eigenschappen van verkochte huizen, en de huizen op basis van overeenkomende patronen in groepen wilt delen, zonder dat de namen van deze groepen al onderdeel zijn van de dataset.
14. Clustering
Clustering is een deelgebied van Unsupervised Learning. Het wordt ook wel segmenteren genoemd en je verdeelt je data in een bepaald aantal groepen, waarbij de datapunten in iedere groep de sterkste onderlinge overeenkomsten hebben.
15. Neural Networks
Neural Networks is een deelgebied van Machine Learning, het staat voor neurale netwerken. De opbouw is gebaseerd op een versimpelde werken van het menselijke brein waarbij neurons (neuronen) met een functie inputs verwerken tot output. Hierbij zijn meerdere neurons in layers (lagen) met elkaar verbonden. Een Neural Network vormt hierdoor een complexe en variabele modelstructuur. Het is te gebruiken om zowel Supervised- als Unsupervised vraagstukken op te lossen.
16. Deep Learning
Deep Learning is een toepassing van Neural Networks. De naam is ontstaan toen door meer beschikbare rekenkracht grotere netwerken getraind en gebruikt konden worden. Je gebruikt Deep Learning typisch voor beeld- en taal-gerelateerde toepassingen.
17. Reinforcement Learning
Reinforcement Learning betekent versterkend leren. Je werkt hierbij niet met een dataset maar binnen een omgeving. Hierdoor is dit een op zichzelf staand gebied binnen Machine Learning. In de omgeving is een agent actief die acties onderneemt, hier feedback van verzamelt, en van de feedback leert. Denk hierbij aan een model (agent) wat in een computerspel keuzes maakt om dingen te doen (acties) en leert van het resultaat om de beste score in het spel te behalen (feedback).
Je hebt nu een goed idee van de terminologie binnen Machine Learning. Hiermee kun je beter begrijpen wat onderlinge relaties en verbanden zijn, en wat je waarvoor kunt gebruiken.
Benieuwd naar je carrièremogelijkheden? Bekijk hier actuele vacatures voor Data Scientists en Machine Learning Engineers in Nederland'.
Machine learning specialist worden?
Wil jij snel op stoom zijn met machine learning? Volg dan onze Data Science opleiding. In vier dagen nemen we je mee in de basis van Python en statistiek. Er is geen voorkennis vereist. Je leert zelfstandig machine learning modellen ontwikkelen en toepassen. Voor wie al ervaring heeft met programmeren in Python is het ook mogelijk om alleen de laatste twee dagen mee te doen; dit is onze machine learning training.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.