Machine learning is een veelgebruikte analyse techniek binnen data science. Als data scientist kun je een machine learning model programmeren in bijvoorbeeld Python. In deze post gaan we in op:
- Wat is machine learning?
- Waarom is machine learning belangrijk?
- Hoe werkt machine learning?
- Hoe leer ik machine learning?
Wat is machine learning?
Machine learning stelt zoals de naam al zegt machines in staat te leren. Vergelijk het met pasgeboden babies die de 'hardware' (hersenen) hebben meegekregen om te leren en door ervaring steeds meer begrijpen.
Ook een machine learning model begint blanco en besluiten en voorspellingen worden beter naar mate de 'ervaring' van het model toeneemt. Er zijn diverse vormen van machine learning die we later in dit artikel toelichten.
Waarom is machine learning belangrijk?
Machine learning klinkt misschien ver van je bed, maar je komt 100% zeker dagelijks met de uitkomsten van machine learning modellen in aanraking. We genereren tegenwoordig zo veel data dat het interpreteren en leren van data niet altijd meer door mensen gedaan kan worden.
Computers zijn bijvoorbeeld in te zetten wanneer je geen begrip van of formules voor data beschikbaar hebt maar er wel inzichten uit wilt destilleren. Een andere reden om machine learning in te zetten kan bijvoorbeeld zijn omdat gedrag voortdurend verandert waardoor je niet uit de voeten kunt met statische analyses. Het kan ook zijn dat de ingegeven data zelf voortdurend aan verandering onderhevig is.
In deze lastige situaties kan machine learning uitkomst bieden. Om het concreet te maken moet je denken aan bijvoorbeeld:
- Een bank die geautomatiseerd witwaspraktijken detecteert
- Steeds betere voorspellingen omtrent de productie van duurzame energie
- Vroegtijdiger en nauwkeuriger detecteren van tumoren
Voor meer voorbeelden en toepassingen kun je deze post bekijken
Hoe werkt machine learning?
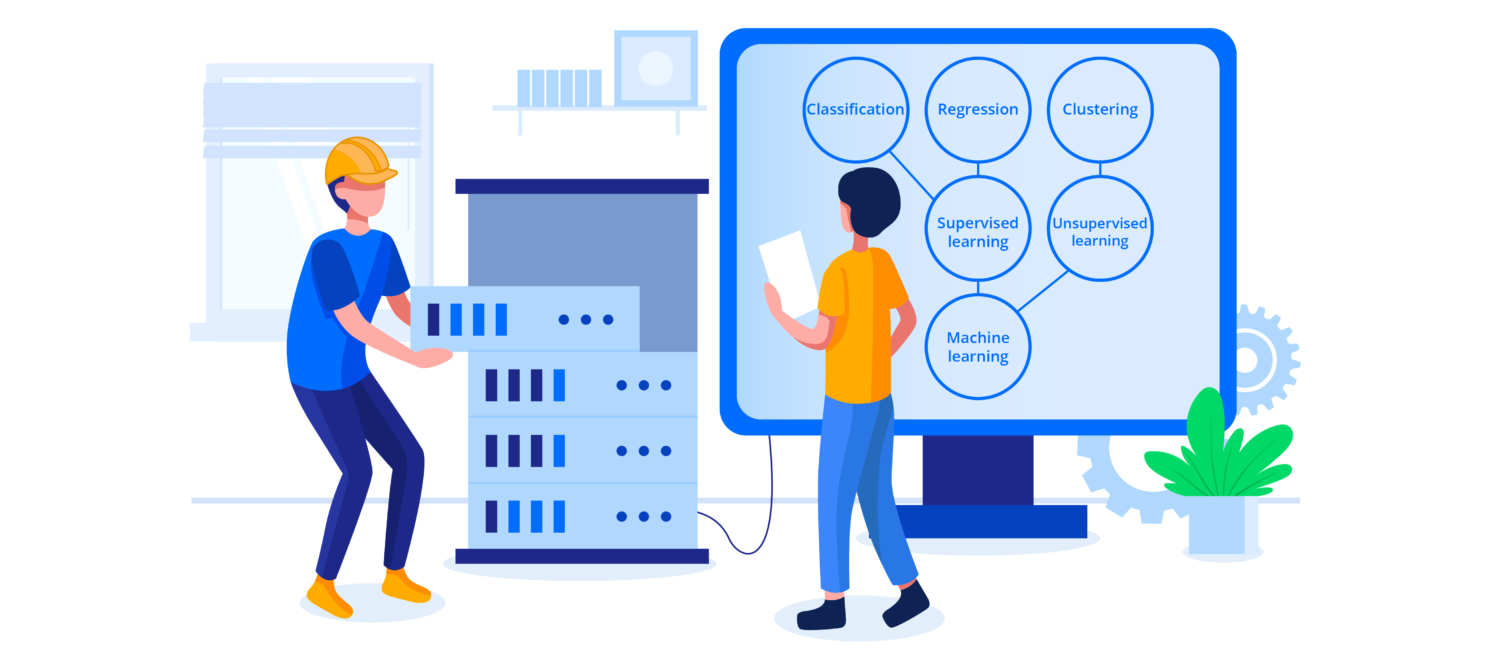
Er zijn verschillende manieren om computermodellen dingen te leren. Om structuur aan te brengen in de verschillende soorten machine learning worden algoritmes veelal gecategoriseerd op leerstijl of op achterliggend statistisch concept. Qua leerstijlen spreekt men binnen machine learning over "supervised learning", "unsupervised learning", of "semi-supervised learning". Qua statistische concepten kun je denk aan bijvoorbeeld "classificatie", "regressie", "clustering", of een "decision tree".
We zullen de concepten nader toelichten:
- Supervised machine learning modellen: deze algoritmes zijn in staat om op basis van voorbeeld-data voorspellingen te doen voor nieuwe data. Je traint het model eerst met veel waarnemingen voor input- en outputvariabelen. Op basis van wat het algoritme ziet gebeuren wordt een steeds nauwkeuriger model ontwikkeld. Het algoritme is ook in staat de eigen voorspellen naast de uiteindelijke uitkomst te leggen zodat het model verder aangescherpt wordt op basis van ervaring.
- Supervised learning gebruikt regressie of classificatie als onderliggen statistisch concept. Voor classificatie is het een voorwaarde dat data gecategoriseerd kan worden. Denk bijvoorbeeld aan: wel of geen fraude-transactie, wel of geen tumor, of het onderscheid tussen onze letters in het alfabet. Algoritmes die hiervoor gebruikt worden zijn bijvoorbeeld decision trees, logistic regression, of nearest neighbour. Hier vind je een machine learning classificatie tutorial
- Regressie technieken voorspellen geen categorieën (wel/niet) maar continue variabelen zoals het percentage kans op een hartaanval of hoeveel tijd je nog hebt voordat machineonderdelen vervangen moeten worden. Regressiemodellen gebruiken bijvoorbeeld (multiple) lineaire regressie en non-lineaire regressie.
- Unsupervised machine learning modellen: deze algoritmes kunnen omgaan met data die nog geen 'label' hebben. Oftewel deze modellen zijn in staat om verborgen structuren zichtbaar te maken.
- Clustering is de meestgebruikte techniek voor unsupervised machine learning. Je gebruikt dit voornamelijk om datasets te verkennen en patronen te ontdekken. Je kunt bijvoorbeeld klantsegmenten herkennen of bepaalde objecten op foto's. Bekende algoritmes zijn bijvoorbeeld k-means en hierarchical clustering.
- Semi-supervised machine learning modellen: deze algoritmen zitten tussen supervised en unsupervised in omdat zij getraind worden met zowel gelabelde als ongelabelde data. Deze combinatie stelt modellen in staat optimaal te leren.
Hoe leer ik machine learning?
Ben jij geïnteresseerd om aan de slag te gaan met machine learning? Op onze website vind je diverse tutorials waarmee je zelf kunt beginnen met machine learning. Het vergt uiteraard discipline en vrije tijd om je door deze tutorials heen te werken. Wie snel tot de kern wil komen kan meedoen met onze tweedaagse machine learning met Python training (let op: hiervoor is Python voorkennis vereist) of met onze vierdaagse data science opleiding waarvan de laatste twee dagen in het teken staan van machine learning (geen voorkennis vereist). In beide trainingen leer je supervised en unsupervised machine learning modellen ontwerpen, trainen, valideren, en in productie brengen. De Python programmeertaal is wereldwijd leidend voor de ontwikkeling van machine learning modellen. Aan Python leren ontkom je dus niet als je serieus met zelflerende algoritmes aan de slag wilt!
Meer informatie vind je in één van onze opleidingsbrochures.

Download één van onze opleidingsbrochures voor meer informatie
Ook interessant: hoe lang duurt Python leren of hoe word ik data scientist

Rik is data scientist en marketeer bij Data Science Partners. Vanuit zijn achtergrond op de Technische Universiteit Eindhoven heeft hij veel affiniteit met data. Na zijn studie heeft hij als consultant altijd met data gewerkt en tevens ervaring opgedaan in het geven van trainingen.