Een Python Boxplot is een door data scientists veelgebruikte visualisatiemethode voor een reeks van datapunten. Uit een boxplot kun je veel aflezen zoals de mediaan, de variatie in de dataset, de skewness, en het aantal outliers. Op deze pagina leggen we uit wat een boxplot is en hoe je een boxplot maakt in Python. We gaan in op hoe je dit doet in de packages Matplotlib, Pandas, en Seaborn.
Wat is een boxplot?
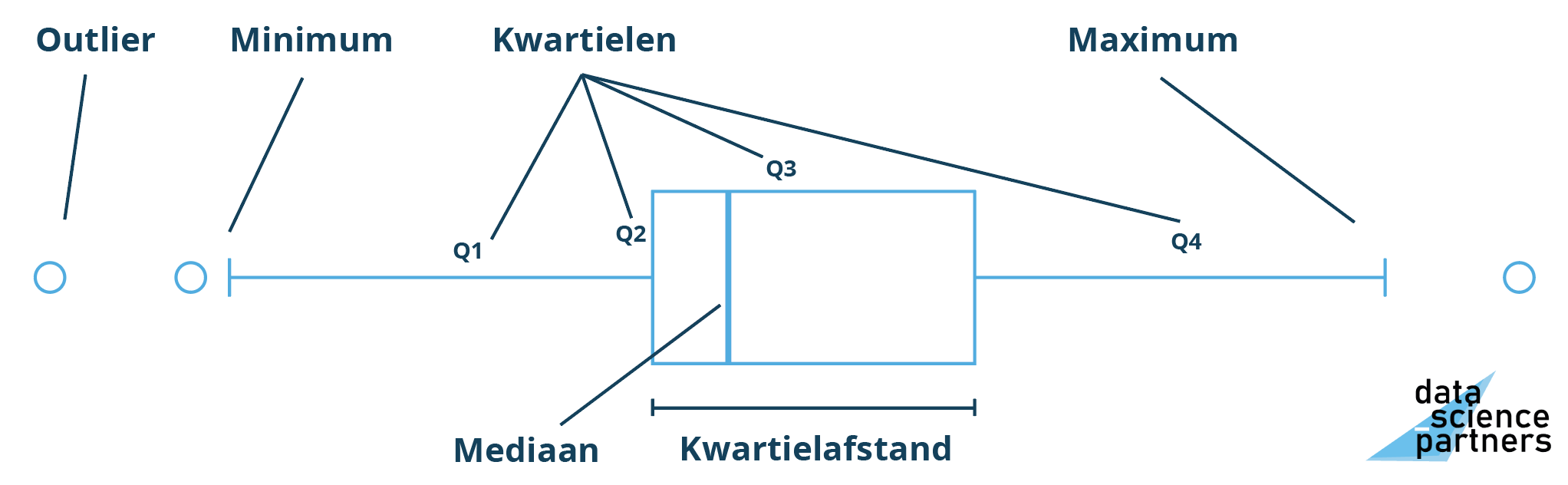
Met een boxplot kun je een reeks datapunten visualiseren. Op deze pagina zullen we gebruikmaken van een dataset met wachttijden in de Nederlandse Geesterlijke Gezondheidszorg (GGZ). We gaan verschillende boxplots voor verschillende typen wachttijden maken. Maar eerst meer over bovenstaande afbeelding. Een boxplot bestaat uit:
- Vier kwartielen (Q1, Q2, Q3, Q4): als je een reeks datapunten van laag naar hoog sorteert, is het eerste kwartiel de eerste 25% van de waarden. Het tweede kwartiel loopt van 25% van de waarde tot de middelste waarde, etc. In een boxplot worden outliers buiten beschouwing gelaten in de kwartielen (zie outlier).
- De mediaan: de mediaan is de middelste waarde uit een reeks datapunten. De mediaan is dus niet per se gelijk aan het gemiddelde van de reeks. De mediaan is robuuster voor reeksen met veel outliers.
- De kwartielafstand: de afstand tussen het einde van het eerste kwartiel en het einde van het derde kwartiel wordt de kwartielafstand genoemd. Oftewel: de middelste 50% van de getallen uit de reeks. De kwartielafstand wordt in een boxplot gebruikt om outliers te bepalen.
- Outlier: als een punt meer dan 1.5 keer de kwartielafstand onder de start van Q2 of boven het einde van Q3 uitkomt, dan wordt het datapunt in de boxplot weergegeven als een outlier.
- Minimum en maximum: in een Python boxplot worden het minimum en maximum weergegeven (outliers buiten beschouwing gelaten).
Hoe maak ik een boxplot in Python met Matplotlib?
Voordat je een boxplot in Python kunt maken zul je enkele voorbereidingen moeten treffen:
- Installeer Python zodat je computer jouw Python scripts kan uitvoeren
- Installeer Jupyter Notebook als je een handige applicatie wilt om jouw scripts in te schrijven en uitvoeren
- Installeer de packages waarmee we gaan werken (Matplotlib, Pandas, Seaborn)
De dataset die we gebruiken bevat wachttijden van de GGZ in Nederland. De dataset is hier te downloaden als je er ook mee wilt experimenteren. We zijn voor onze Python boxplots in het bijzonder geïnteresseerd in de wachttijden. In de dataset vind je twee soorten wachttijd:
- De aanmeldtijd: dit is gedefinieerd als de tijd in weken tussen het aanmelden en het intakegesprek
- De behandeltijd: dit is gedefinieerd als de wachttijd in weken tussen het intakegesprek en de daadwerkelijke behandeling
We starten met het importeren van het package Pandas en het inlezen van de dataset. We checken of de column namen corresponderen met onze verwachting.
import pandas as pd
df = pd.read_csv('data.csv', sep=';', encoding='latin-1')
df.columns
We zijn geïnteresseerd in de 'Aanmeldtijd' en 'Behandeltijd'.
aanmeldtijd = df['Aanmeldtijd'].str.replace(',','.').astype(float).dropna()
behandeltijd = df['Behandeltijd'].str.replace(',','.').astype(float).dropna()
Nu we de aanmeldtijd en behandeltijd hebben opgeslagen kunnen we de boxplots maken. We importeren de packages numpy en matplotlib. Met '%matplotlib inline' zorgen we ervoor dat we in Jupyter Notebook direct de visualisaties plotten als we het script uitvoeren. Met onderstaande code realiseren we boxplots voor de twee soorten wachttijden. Hier vind je documentatie over plt.boxplot()
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.boxplot([aanmeldtijd, behandeltijd])
plt.show()

We zien dat Matplotlib standaard een vrij kale grafiek teruggeeft. Je kunt deze grafiek op alle vlakken mooier en duidelijker maken door informatie weg te halen of toe te voegen, of door de opmaak te veranderen. We voegen wat zaken toe.
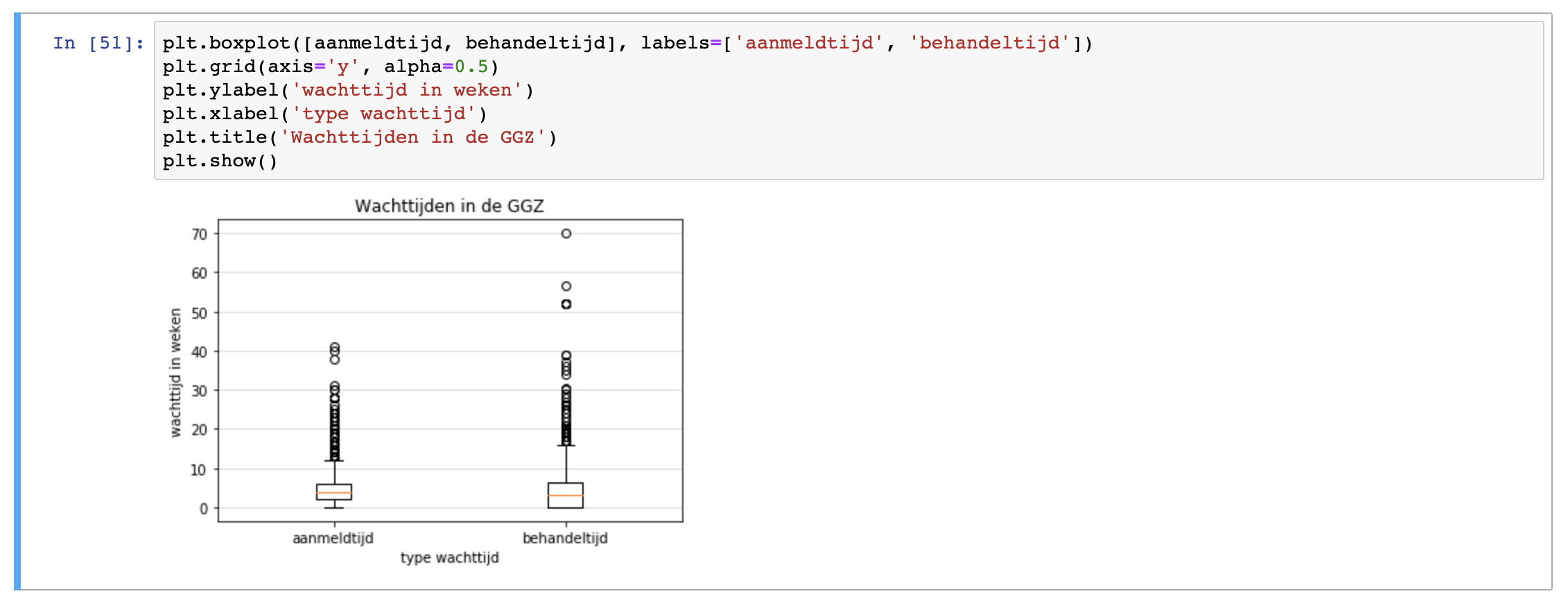
plt.boxplot([aanmeldtijd, behandeltijd], labels=['aanmeldtijd', 'behandeltijd'])
plt.grid(axis='y', alpha=0.5)
plt.ylabel('wachttijd in weken')
plt.xlabel('type wachttijd')
plt.title('Wachttijden in de GGZ')
plt.show()

We zien dat de tijd tussen de aanmelding en het intakegesprek over het algemeen korter is dan tussen het intakegesprek en de uiteindelijke behandeling. Beide boxplots tonen veel outliers. Dit betekent dat er vrij veel behandelingen zijn bij instellingen die een uitzonderlijk lange wachttijd hebben voor een intakegesprek of een behandeling. We zien beide boxplots stoppen bij nul weken. Er zijn dus blijkbaar ook behandelingen die vrijwel altijd direct in intake kunnen en daarna van start gaan. De mediaan ligt om en nabij de 4 weken. Voor de helft van de behandelingen heb je dus gemiddeld genomen binnen een maand een intakegesprek en binnen een maand daarna start de behandeling. Verder zien we een grotere spreiding in de wachttijd voor behandeling dan in de wachttijd voor intakegesprekken. Gevoelsmatig is dit geen vreemde bevinding.
Hoe maak ik een boxplot in Python met Pandas?
Pandas is het meestgebruikte data science package voor Python. Binnen Pandas kun je direct gebruik maken van Matplotlib. Je kunt DataFrames direct visualiseren in een boxplot met DataFrame.plot.box().
aanmeldtijd.plot.box()
plt.show()

Hoe maak ik een boxplot in Python met Seaborn?
Seaborn is een package dat ontwikkeld is voor visualisatie in Python. Ook Seaborn maakt gebruik van Matplotlib. Het is echter zo dat Seaborn standaard een wat mooier design heeft en dat het makkelijker is om verschillende doorsnedes van datasets te laten zien.
In dit package is het ook mogelijk om met weinig moeite een Boxplot te realiseren met sns.boxplot():
import seaborn as sns
sns.boxplot(x=behandeltijd)
plt.show()

Maar stel dat we willen weten hoe de totale wachttijd per zorgcircuit verdeeld is? We voegen 'Circuit' toe aan ons dataframe en tellen de Aanmeldtijd en de Behandeltijd bij elkaar op om tot de totale wachttijd te komen.
wachttijden = df[['Aanmeldtijd', 'Behandeltijd', 'Circuit']]
wachttijden['Aanmeldtijd'] = wachttijden['Aanmeldtijd'].str.replace(',','.').astype(float)
wachttijden['Behandeltijd'] = wachttijden['Behandeltijd'].str.replace(',','.').astype(float)
wachttijden['Totale wachttijd'] = wachttijden['Aanmeldtijd'] + wachttijden['Behandeltijd']
wachttijden = wachttijden.dropna()
wachttijden.head()
sns.boxplot(data=wachttijden, x='Circuit', y='Totale wachttijd')
plt.show()

Wat valt op uit deze visualisatie:
- Bij volwassenen en adolescenten zie je de meeste uitschieters, terwijl in andere circuits de wachttijden minder uit elkaar liggen.
- De behandeling van ouderen en verslaafden begint over het algemeen een stuk sneller dan bij volwassenen en adolescenten. Ook is de spreiding veel lager.
- Jongeren moeten het langst wachten op een behandeling.
Met Seaborn kun je gemakkelijk allerlei doorsneden maken. We illustreren dit met een voorbeeld waarbij we de aanmeldtijd, behandeltijd, en totale wachttijd per zorgcircuit visualiseren.
sns.catplot(data=wachttijden, col='Circuit', kind='box')
plt.show()

Wil je leren hoe je data visualiseert in Python?
In onze tweedaagse Python cursus voor data science nemen we je mee in de mogelijkheden van Python. We gaan uitgebreid aan de slag met analyses en visualisaties. In onderstaande brochure vind je meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Rik is data scientist en marketeer bij Data Science Partners. Vanuit zijn achtergrond op de Technische Universiteit Eindhoven heeft hij veel affiniteit met data. Na zijn studie heeft hij als consultant altijd met data gewerkt en tevens ervaring opgedaan in het geven van trainingen.