
Wat is supervised learning?
Supervised Learning is een machine learning methode waarin je werkt met gelabelde data waarmee je voorspellingen wilt doen. Gelabelde data betekent hier dat de dataset die je gaat gebruiken om te modelleren zowel de eigenschappen, als de uitkomst van hetgeen wat voorspeld moet worden bevat.
Stel je dit als volgt voor: je wilt een model maken waarmee op basis van eigenschappen van een woning de waarde van de woning voorspeld kan worden, en je gebruikt hiervoor een historische dataset met hierin eigenschappen van meerdere woningen en van elk van de woningen de verkoopprijs.
Letterlijk betekent Supervised Learning begeleid leren. Doordat je bij Supervised Learning altijd met een dataset werkt die het beoogde voorspellingsresultaat bevat, kan het model begeleid getraind worden.
Dit in tegenstelling tot Unsupervised Learning, (onbegeleid leren) waarbij in de trainingsdataset het beoogde voorspellingsresultaat niet voorkomt. Je kunt hierdoor bij Supervised Learning na het trainen van een model altijd de voorspellingen vergelijken met de werkelijkheid, en hiermee bijvoorbeeld de nauwkeurigheid van het model berekenen. Je doet dit over het algemeen door je originele dataset op te splitsen in 80% traindata waarmee je het model traint, en 20% testdata waarmee je de voorspellingskwaliteit van het model valideert.
De eerste Supervised Learning algoritmes zijn ontstaan in de jaren 50 van de 20e eeuw. De modellen die hieruit volgden werden toen vooral gebruikt voor het herkennen van patronen in data. Momenteel werkt nog een groot deel van alles wat wat een data scientist met data doet op dit gedachtegoed.
Supervised Learning algoritmes zijn over het algemeen relatief simpel en zijn daardoor makkelijk toe te passen. De simpliciteit heeft ook een keerzijde, namelijk dat er lagere nauwkeurigheden behaald worden in vergelijking met bijvoorbeeld een Neural Network of een Ensemble Method. Dit hoeft overigens niet altijd erg te zijn.
Binnen Supervised Learning bestaan er 2 subgroepen:
- Regressie: voor het voorspellen van een waarde, een getal
- Classificatie: voor het voorspellen van een categorie, een groep
We gaan stap voor stap door deze verschillende subgroepen heen om de ins en outs te verduidelijken.
Supervised learning met Regressie
Met regressie (regression in het Engels) modellen kan een waarde, een getal, voorspeld worden. Denk hierbij bijvoorbeeld aan het voorspellen van:
- Huizenprijzen
- Aandelenkoersen
- Verkoopvolumes
- Productietijden
Stel je voorspelt huizenprijzen, je bent dan in het bezit met een dataset met gegevens van verkochte huizen, en de verkoopprijzen van deze huizen. Je gebruikt deze data om een algoritme te trainen tot een model, waarmee je op basis van gegevens van andere huizen kan gaan voorspellen wat hiervan de verkoopprijzen zullen zijn.
Bij het maken van een regressiemodel heb je dus altijd uit je dataset de werkelijke waarde, en je model geeft een voorspelde waarde. De verschillen tussen voorspellingen en werkelijkheid kun je gebruiken om te bepalen hoe betrouwbaar je model is.
Bekende regressiealgoritmes
Er verschillende algoritmes waarmee regressievraagstukken gemodelleerd kunnen worden. Bekende algoritmes zijn:
- Linear Regression (lineaire regressie)
- Hierbij trek je een best passende rechte lijn door de datapunten, in de bekende vorm y=ax+b, wat bij regressie vaak wordt geschreven als y=w0+w1x
- Denk hierbij bijvoorbeeld aan dat je de omzet van je bedrijf vanuit telefonische marketing wilt voorspellen:
- y=w0+w1x
- Voorbeeld: omzet = 20 + 2 * aantal telefoongesprekken
- Polynomial Regression (polynoom regressie)
- Hierbij trek je een best passende polynoom door de datapunten, in de vorm y=w0+w1x+w2x2
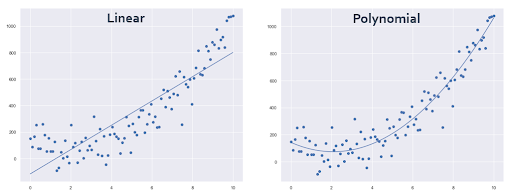
Je kunt in je model altijd één of meerdere voorspellende eigenschappen meenemen. Deze eigenschappen worden ook wel features genoemd. Feature Engineering is de naam van het proces waarbij je de eigenschappen selecteert, bewerkt of maakt zodanig dat je je model kan trainen met op de best voorspellende eigenschappen.
Beoordelen van regressiemodellen
Naast verschillende algoritmes zijn er specifieke methoden waarmee de kwaliteit en betrouwbaarheid van regressiemodellen gekwantificeerd kunnen worden.
Bekende termen en methoden bij het beoordelen van regressiemodellen zijn:
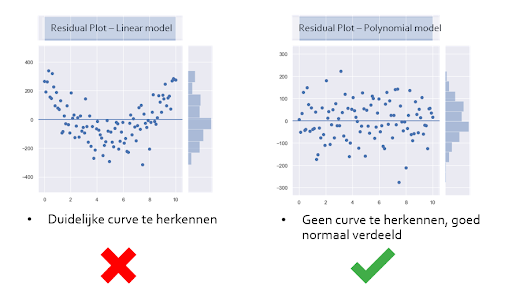
- Residual plot
- Plot voor elke voorspelling de afwijking (afwijking = werkelijke waarde - voorspelde waarde)
- Hierin kijk je of er vreemde vormen waar te nemen zijn
- Determinatiecoefficient (R²)
- Een getal tussen 0 en 1 wat de spreiding al dan niet verklaard door het model weergeeft, een waarde dichter bij 1 is beter
- Mean Absolute Error (MAE)
- Het gemiddelde van absolute errors, afwijkingen
- Mean Squared Error (MSE)
- Het gemiddelde van gekwadrateerde errors
- Root Mean Squared Error (RMSE)
- De wortel van MSE
- Mean Absolute Percentage Error (MAPE)
- De gemiddelde procentuele absolute error
Under- en Overfitting
Een probleem bij regressiemodellen kan under- of overfitting zijn. Het model moet voldoende gegeneraliseerd zijn zodat het enerzijds voldoende meebeweegt met spreiding in de data (anders heb je underfitting), en anderzijds niet te veel meebeweegt met spreiding in de data (anders heb je overfitting. Dit is geïllustreerd in onderstaande figuur.
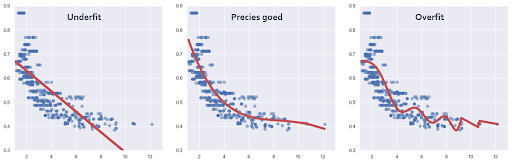
Dit mogelijke probleem wordt ook wel de Bias-Variance Tradeoff genoemd. Je kunt het voorkomen door:
- Meer traindata te gebruiken
- Regularization toe te passen
- Een aanpassing in je algoritme waardoor overfitting tegen wordt gegaan
Met de methode Cross Validation verdeel je je dataset in meerdere delen, waarbij je het algoritme op elk van de delen traint en zo meerdere modellen krijgt. Je kunt deze methode zo ook gebruiken om de aanwezigheid van vooral overfitting te valideren. Wanneer je model perfect presteert op de data waarmee het getraind is, maar belabberd op nieuwe data, dan weet je dat je te maken hebt met overfitting.
De besproken techniek is open-source beschikbaar binnen Python packages. Hier vind je een overzicht van python packages en hier kun je meer lezen over leren van Python.
Supervised Learning met Classificatie
Met classiciatie (classification in het Engels) modellen kan een categorie, een groep, voorspeld worden. Hierbij voorspel je ofwel het label van de groep, of de kans op de groep.
Denk bij het label van een groep bijvoorbeeld aan: bevat deze afbeelding een appel of een peer, is deze e-mail spam of geen spam. Denk bij de kans op een groep bijvoorbeeld aan: wat is de kans dat deze afbeelding een appel bevat, wat is de kans dat deze e-mail een spambericht is.
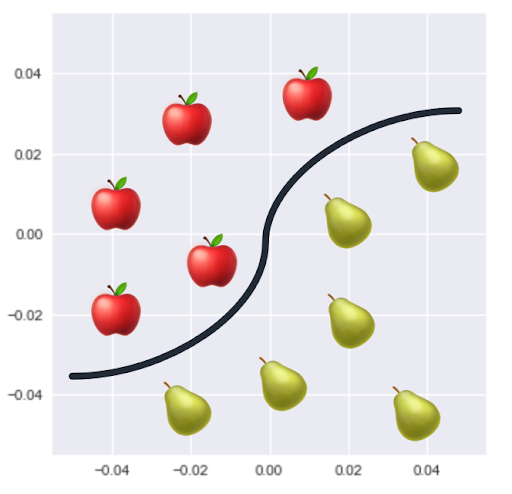
Classificatiemodellen worden in de praktijk gebruikt bij bijvoorbeeld:
- Fraudedetectie
- Handschriftherkenning
- Taalherkenning
- Spamfilters
Beoordelen van classificatiemodellen
Er zijn verschillende algoritmes waarmee classificeringen verricht kunnen worden. Tevens zijn er specifieke methoden om de kwaliteit en betrouwbaarheid van classificeringen te kunnen kwantificeren.
Bekende termen en methoden bij het beoordelen van classificatiemodellen zijn:
- Threshold: Vanaf welke voorspelde kans reken je een voorspelling bij groep A?
- Voorbeeld: Als de kans op een appel groter is dan 0.5 (Threshold = 0.5) classificeren we de afbeelding als appel
- Confusion Matrix: Een tabel met hierin de relaties tussen positieve en negatieve voorspellingen (bijvoorbeeld wel spam / geen spam) en de werkelijkheid (email is werkelijk spam / geen spam)
- Metrics: Statistische samenvatting van de voorspellingskwaliteit
- Accuracy: Hoe vaak voorspelt het model correct?
- Precision: Als het model positief voorspelt, hoe vaak is dit correct?
- Recall: Wel deel van de werkelijk positieve waarden is juist voorspeld?
- Specificity: Welk deel van de werkelijk negatieve waarden is juist voorspeld?
- F1 score: Het harmonische gemiddelde van Precision en Recall
- Grafieken
- ROC AUC: De verhouding tussen Recall en 1-Specificity voor verschillende waarden als Threshold geplot in een grafiek. Het oppervlak onder de lijn heet AUC. Hoe hoger dit oppervlak hoe beter.
- PR AUC: De verhouding tussen Precision en Recall voor verschillende waarden als Threshold geplot in een grafiek. Ook hier geldt dat hoe groter het oppervlak onder de lijn (AUC) is, hoe beter dit is.
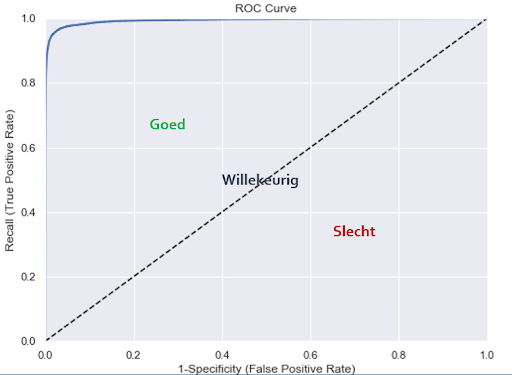
Bekende classificatiealgoritmes
Zoals eerder vermeld zijn er verschillende algoritmes waarmee classificatievraagstukken gemodelleerd kunnen worden. Bekende algoritmes zijn:
- Naive Bayes: Vergelijk met kansberekening 2 situaties (A en B)
- Logistic Regression: Zet elke getallenreeks om in een waarde tussen 0 en 1 met behulp van regressie en de Sigmoid functie
- Decision Tree: Verdeel de data met vragen zodat een beslisboom ontstaat
- Support Vector Machine (SVM): Splits de groepen door met lijnen (vectoren) de beste scheiding tussen de groepen af te bakenen
- k-Nearest Neighbor (kNN): Bepaal het gemiddeld van het aantal k dichtsbijgelegen datapunten
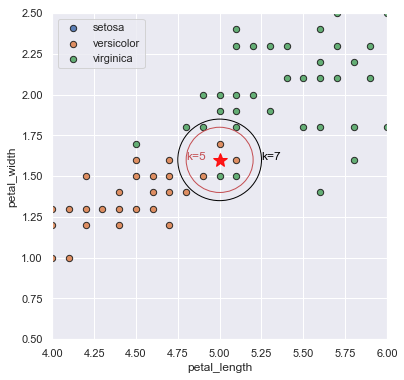
Ongebalanceerde datasets bij classificatie
Het is een gebruikelijke uitdaging dat de ene groep significant sterker vertegenwoordigd is dan de andere. Denk hierbij bijvoorbeeld aan de situatie dat je een dataset hebt met gegevens van 80 normale e-mails, en slechts van 20 spamberichten. Wat nu kan ontstaan heet ook wel de Accuracy Paradox, een model kan overfitten op de grootste groep waardoor die groep goed voorspeld wordt, maar de kleine groep totaal niet.
Er zijn meerdere oplossingen, denk hierbij aan:
- Meer data (Geeft wellicht al een betere verdeling)
- Gebruik andere metrics (F1 score, PR AUC)
- Pas resampling toe (Zorg zelf voor balans)
- Voeg synthetische samples toe (SMOTE methode)
- Gebruik andere algoritmes (Decision Tree)
Wat je moet onthouden
We hebben geleerd dat Supervised Learning begeleid leren betekent. Het is een veelgebruikte data science techniek en wordt veelal uitgevoerd in Python. In Supervised Learning is er altijd data beschikbaar om de juistheid van de voorspelling uit een model te valideren. Binnen Supervised Learning zijn er 2 subgroepen: regressie en classificatie.
Met regressiemodellen voorspel je een waarde, een getal. Met classificatiemodellen voorspel je een categorie, een groep. Voor zowel regressie- als classificatiemodellen zijn er specifieke metrics om de kwaliteit en betrouwbaarheid van een model te meten, ook zijn er voor beide soorten voorspellingen verschillende algoritmes die je kunt gebruiken om een model te trainen.
Supervised Learning met regressie en classificatie is onderdeel van onze data science opleiding en machine learning training. Dus wil jij je ontwikkelen of omscholen tot data scientist en in staat zijn om bijvoorbeeld huizenprijzen te voorspellen? Schrijf je dan in of neem contact met ons op voor meer informatie.

Download één van onze opleidingsbrochures voor meer informatie

Peter is een ervaren data scientist en python trainer. Na zijn studie aan de Technische Universiteit Delft heeft hij zich altijd bezig gehouden met data en diverse programmeertalen. Peter heeft veel data analyses uitgevoerd en processen geautomatiseerd met Python in productieomgevingen.









